Motivation
Apache Kafka is a persistent, replicated message broker, streaming- and data integration platform. It is typically used a central data hub and streaming component in a fast data architecture.
Overview and terminology
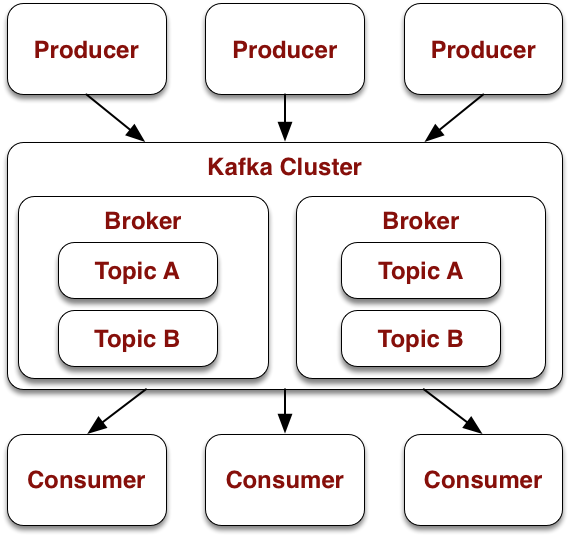
Kafka collects messages and persists them on disk. Messages are data that are published and received (publish-subscribe).
Kafka is distributed over multiple nodes, called broker, to scale out and to provide high availability. A Kafka cluster is coordinated via Apache ZooKeeper.
Messages are collected in named containers called topics. New messages are appended to the end of a topic, and they receive an increasing number. This number is called offset. Kafka is also called a log in the sense of a consecutive sequence of messages. Each topic replicated onto multiple brokers.
Each topic is separated into partitions. The number of partitions is determined upon topic creation and it defines how the topic scales. The messages in the topic are distributed over the partitions. The offset is per partition.
Producers publish messages into topics. Consumers subscribe to topics and read the incoming messages in a continuous stream.
Persistence
Kafka persists each received message on disk in segments. Each segment is a file that contains a certain configurable amount of messages before a new segment will be opened.
Despite writing all messages to disk, Kafka has very high performance. This is achieved by appending messages at the end of the always-open segment file and by scaling via partitions. All writes go to the Linux page cache, reads come from the page cache via a network socket. Unlike a typical database, upon writing data no index must be maintained, only the offset is increased.
In general, SSDs are recommended, but thanks to this design, normal disks are also performing quite well.
In contrast to other message queues, data in Kafka is not removed after consuming them.
Topics
Overview
A topic is a collection of messages with a unique name. Kafka doesn’t specify what kind of data lands in a topic, for Kafka itself it’s only a container that has a certain name and certain configuration parameters. In each topic, messages are written to the end (append-only).
Each topic is created explicitly with a replication factor and a number of partitions. Many config parameters in Kafka are per topic or can be overwritten by the topic’s configuration.
Partitions

Each topic is separated into sub-units, it is partitioned. Partitions are the basic mechanism by which both scaling as well as replication are achieved. If a topic is being written or read from, this is always related to specific partitions. The offset is also per partition.
Each partition is sorted by its offset. If you write a message to a topic, you can specify a key for the message. By taking the hash of the key, all messages with the same key are written to the same partition. Message ordering is guaranteed within one partition.
Segments
Finally, each partition maps to several segment files on disk. New message are saved to the active segment. As soon as the segment hits the configured size or time limit, it will be closed. A new segment will be created and in turn become the active segment.
Each segment file is named after the offset of the first message it contains and ends with .log.
For that there’s a matching index file that maps the offsets to the positions of the messages in the segment file.
Example: A broker that holds the “Test” topic’s partitions 0 and 2 with 100 messages per segement, you would see the following folder structure:
|- /tmp/kafka-logs/
|-- Test-0/
|---- 00000000000000000000.index
|---- 00000000000000000000.log
|---- 00000000000000000101.index
|---- 00000000000000000101.log
|-- Test-2/
|---- 00000000000000000000.index
|---- 00000000000000000000.log
A high amount of partitions means you can write and read more data in parallel, but also that there are more file handles open and more threads are used. When using too few partitions, parallelism can be too low.
If only a low number of messages should be processed, a low number of partitions is enough. You typically start with a small value and increase it over time. Increasing the number of partitions is straightforward, reducing partitions is not possible because it would mean data loss.
Log retention
For every topic a time-to-live (TTL), or its inverse retention, can be defined, either per time
(parameters log.retention.hours, log.retention.minutes, log.retention.ms), by size (parameter log.retention.bytes),
or both. The biggest limiting factor is typically disk size, topics could in theory have a TTL of a year or more.
If retention is enabled, Kafka removes all messages that have surpassed the maximum age. When using a size limit,
closed segments are removed as soon as the bytes limit is reached in all partitions combined. The active segment always
stays untouched.
There are also a special kind of topic called compacted topics that only keep the latest version of a message. Old messages with the same key are deleted in regular intervals. A message without content (=null) deletes all messages with the given key.
Replication, Leader and Replicas

As mentioned earlier, Kafka is distributed over multiple brokers and replicates topics for reliability. Partitions are the means to enable replication in a simple way. Each node is either the partition’s leader, or replica.
A topic’s replication factor determines on how many brokers each partition is replicated. A factor of 2 would mean that every partition would be saved on the leader and one replica. A partition with factor r exist r-times in the cluster.
So it’s not the topic but each single partition that has one leader partition and r-1 followers. The leader partition is simply the partition on its assigned leader broker. Which broker is the leader for which partition is determined upon topic creation via round robin, but can also be assigned manually via partition maps. This is even necessary when the number of partitions must be changed.

Writing happens on the leader, then is distributed to the replicas
In-Sync Replica (ISRs) are those replicas that have caught up to the leader. If a leader crashes, a new leader is elected from the pool of ISRs. This way, r-1 ISR in the cluster can fail without suffering data loss.
When creating a topic, the replication factor cannot be higher than there are brokers in the cluster. This doesn’t sound too special but it means that when some brokers are down, then it’s possible that a topic cannot be created that otherwise could, as there are not enough brokers available. When brokers are down and the replication factor of an existing topic can no longer be met, the partitions from the unavailable brokers are marked as under-replicated.
New data is not pushed, instead replicas pull from the leader.
Messages
A message’s content is a sequence of bytes. A key can be assigned to the message, likewise a sequence of bytes. Then there is metadata like offset, checksum, message size, compression type, and timestamp. Lastly you can also add custom headers to the message.
The content and the key, and by extension their format, is completely in the hand of the user. Kafka’s client API only offers de-/serializers for Strings and byte arrays. A custom de-/serializer must always read or write a byte array in order for Kafka to process the data.
Message or rather batches of messages can and should be compressed. Kafka is able to save compressed data directly without unpacking it. The compression format is noted in the meta data. Enabling compression is one of the biggest performance wins when using Kafka.
Messages also have a header that consists, just like HTTP, of key value pairs. Headers are used when you want to decide about how to process the data without knowing the message’s content. For example could the header specify the data format via a Content-Type (JSON, Avro, Protobuff, and so on). Or it is forbidden to access the data at all when the data is encrypted or should not be accessible because of data privacy. A typical example for this would be when data is created in Europe and should not be replicated to US data centers.
Producers
Overview
A producer writes messages into topics.
When sending a message, a key can be set. Kafka uses the key’s hash value to determine in which partition the message should be written. Is no key set, a random partition is chosen. In the beginning, the producer connects to any broker in the cluster that then identifies the partition leader to which the producer transmits the message.
A Kafka producer works asynchronously and writes its messages in batches. Both the batch size and a maximal wait time until a batch is sent can be configured to optimize for either throughput or latency.
Durability
An important configuration parameter is acks. It controls reliability and throughput. If acks is set to 0,
messages are sent fire-and-forget style. There are no guarantees that a message was written, but throughput is
the highest possible. This mode is relevant for unit tests that should be executed as fast as possible.
Is acks set to 1, the leader’s acknowledgement is enough. Every other number n requires leader + n-1 replicas
acknowledgements. Finally, all means that configured minimal number of ISRs (broker config min.insync.replicas)
have to acknowledge the write.
The more acknowledgements there are, the safe the write is, but the lower the performance. If acks’ requirements cannot be met at all, an exception is thrown.
Compression
Compression (config compression.type) should always be enable. By default, snappy is used, but depending on the
environment other algorithms such as LZ4 offer a better performance. Topics themselves can be compressed. If you
choose producer as compression type, then not only is the same algorithm as in the producer being used, but Kafka
actually saves CPU time because it doesn’t have to extract and re-compress incoming messages, as it can directly
zero-copy the messages.
Consumer
Overview
A consumer reads messages from one or multiple topics.
A Kafka consumer is not notified via push, but instead polls for new messages and thus controls at which pace it receives data.
A message’s key is also important when processing data. When data is partitioned by user ID for example, a consumer knows that it receives all the user’s data. The user data can not reside in other partitions that are assigned to another consumer.
Offsets
The current position of a consumer in the log is managed using the message offset. The offset is the means to keep track of which messages have already been processed. In order not to reprocess the same messages again when a consumer crashes or restarts, the lastly processed offset must be save to jump to the right position.
Consumer lag is when a consumer has not processed all messages yet, its offset is smaller than the partition’s highest available offset. Messages are then produced faster than they are consumed.
The offset can be stored automatically in Kafka’s own topic _offsets (many parts of Kafka are implemented using
Kafka itself). This is extremely easy to use, as Kafka then also manages jumping to the last offset when the
consumer restarts. This method also allows to write transactionally from one topic into another.
Alternatively it is very well possible to manage offset manually. It can for example be useful to save the offset to a database that can be queried by monitoring tools. Additionally you can easily reset the offset if some processing has failed and has to be done again (replay). Finally it can help to avoid consuming messages repeatedly when the offset is saved with the data that was processed (although in newer versions of Kafka, this can also be achieved using exactly-once processing).
Consumer Groups

two partitions are assigned to the second consumer and it hasn't processed all messages yet (consumer lag)
Consumers are organized in groups. Group membership is managed via the config parameter group.id.
When a consumer that is member of a consumer group is startet, all other consumers in the group are rebalanced.
The same thing happens when a group member crashes. It is important to understand that not all members of a group
receive all data, but the data is distributed within the group. This is achieved by assigning each partition to
exactly one consumer in the group. Each consumer can read from one or more partitions.
This is why the number of partitions is the upper parallelism limit. If you want to read at a high level of parallelism, you have to have an according number of partitions. If each consumer has one partition assigned, so the number of consumers equals the number of partitions, another consumer would simply receive no data. On the other hand a high number of partitions increases memory pressure on the JVM as each consumer starts one thread per partition. One consumer per partition can also be wasteful as one service can process more than partition without lagging behind in a lot of cases.
Groups are also used to process the same data in different use cases. For example, one group might want to process the stream in real-time, while another is only started each night to batch process all data.
Eco system
Kafka itself only consists of the core of persistent messages and producer and consumer APIs. Around Kafka there are several tools that help to achieve typical tasks like monitoring and stream processing.
Included Tools
Mirror Maker is a producer and a consumer and mirrors topics from one cluster to another. This can also be used for cross-data center replication.
Kafka Connect is an ETL tool that loads data from and to Kafka. A typical use case is to connect relational databases and load their data into a Kafka topic. This achieved by JDBC connectors or using the change data capture (CDC) functionality that most databases offer. Each change in the database is then published as an event in Kafka.
Kafka Streams is a stream processing library that only works with Kafka because it relies on specific features of Kafka. It is useful for both streaming ETL, and to implement Microservices. A notable feature is that Kafka streams services usually keep local state, for example a table, that is built from a compacted topic.
ksqlDB allows to query and transform data from topic using SQL. Since new messages are continouosly arriving in topic, queries are also streamed. It supports pull and push queries. kSQLDB runs as a service on the Kafka cluster and is ideal for all processing that can be modeled using SQL.
Separate Tools
CMAK, Cluster Manager for Apache Kafka, is a web-based tool that allows you to manage your Kafka cluster.
Trifecta is a web-based tool to show and query the data in your topics.
Alternatives
Amazon Kinesis is part of the Amazon Web Services (AWS) offering, and thus is a cloud based message queue and streaming platform. Kinesis is ideal when you don’t want handle the infrastructure and want to integrate with other AWS services lie Lambda or Elastic MapReduce (EMR). In general, Kafka scales better than Kinesis, and AWS also offers Kafka in the cloud using Managed Streaming for Apache Kafka (MKS).
Apache Pulsar is somewhat younger than Kafka and some interesting features like separating reads and writes using Apache BookKeeper, geo replication, and in general more features directly in the broker.